An overview of deep learning for image processing
Deep learning revolutionized image processing. It made previous techniques, based on manual feature extraction, obsolete. This article reviews the progress of deep learning, with ever-growing networks and the new developments in the field.
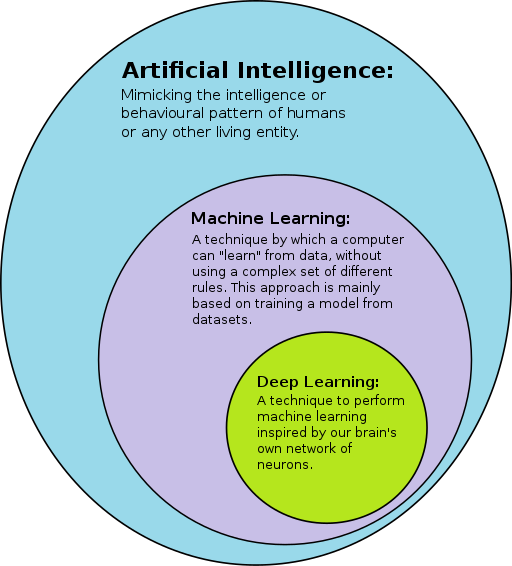
Deep learning is a sub-area of machine learning, which in turn is a sub-area of artificial intelligence (picture source).
{kind=link}
The best way I found to explain deep learning is in contrast to traditional methods. Yann LeCun, one of the founders of deep learning, gave an informative talk on the evolution of learning techniques, starting with the traditional ones and ending with deep learning. He focuses on image recognition in that talk.
It is a worthwhile investment of one hour of our time to listen to someone who was not only present but actively driving the evolution of deep learning. The two pictures immediately below are from his speech.
Traditional image recognition vs. deep learning
In traditional image recognition, we use hand-crafted rules to extract features from an image (source).

In contrast, deep learning image recognition is done with trainable, multi-layer neural networks. Instead of hand-crafting the rules, we feed labeled images to the network. The neural network, through the training process, extracts the features needed to identify the images (source).

“Deep” comes from the fact that neural networks (in this application) use several layers. For example, LeNet-5, named after Yann LeCunn (of the presentation above) and shown in the (historic) picture below (source), has seven layers.
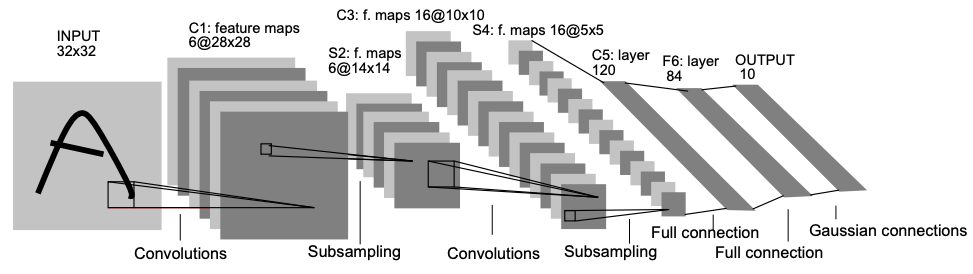
What deep learning networks “learn”
Each layer “learns” (“extracts” is a better technical term) different aspects (“features” in the pictures above) of the images. Lower layers extract basic features (such as edges), and higher layers extract more complex concepts (that frankly, we don’t quite know how to explain yet).
The picture below (source) shows the features that each layer of a deep learning network extracts. On the left, we have the first layers of the network. They extract basic features, such as edges. As we move to the right, we see the upper layers of the network and the features they extract.

Unlike traditional image processing, a deep learning network is not manually configured to extract these features. They learn it through the training process.
The evolution of deep learning
Deep learning for image processing entered the mainstream in the late 1990s when convolutional neural networks were applied to image processing. After stalling a bit in the early 2000s, deep learning took off in the early 2010s. In a short span of a few years, bigger and bigger network architectures were developed. Over time, what “deep” meant was stretched even further.
The table below shows the evolution of deep learning network architectures.
| When/What | Notable features | Canonical depiction |
|---|---|---|
| 1990s LeNet |
Trainable network for image recognition. - Gradient-based learning - Convolutional neural network |
|
| 2012 AlexNet |
One network outperformed, by a large margin, model ensembling (best in class at the time) in ImageNet. - Deep convolutional neural network - Overcame overfitting with data augmentation and dropout |
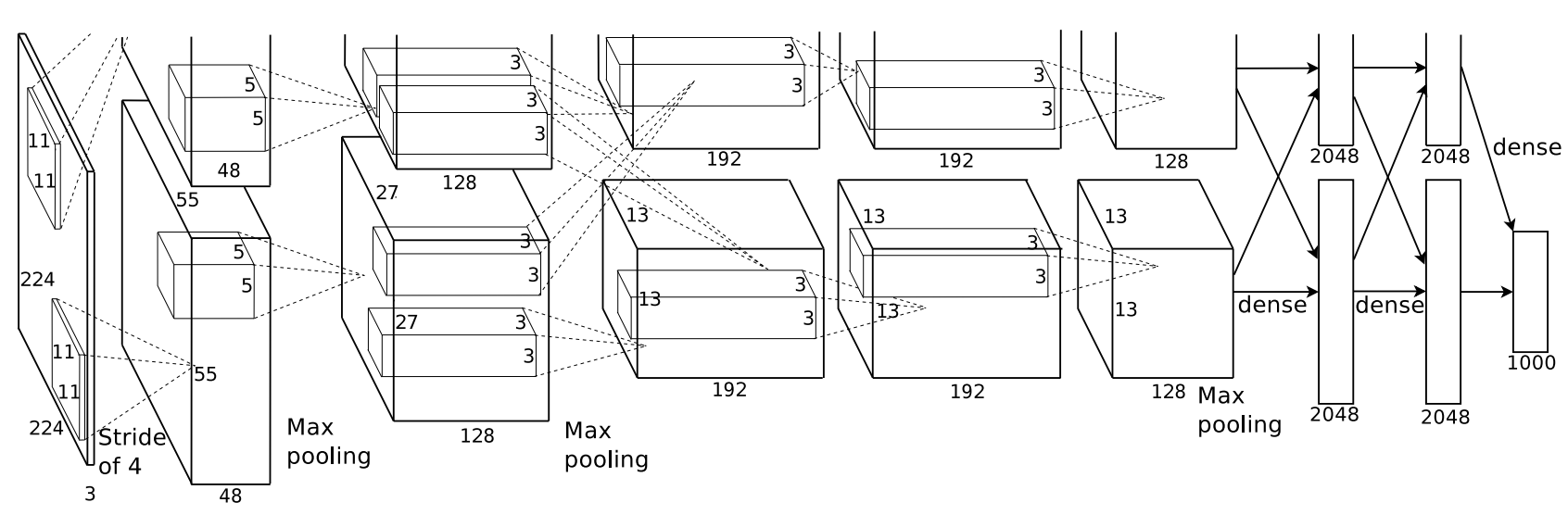 |
| 2014 Inception (GoogLeNet) |
Very deep network (over 20 layers), composed of building blocks, resulting in a “network in a network” (inception). | Partial depiction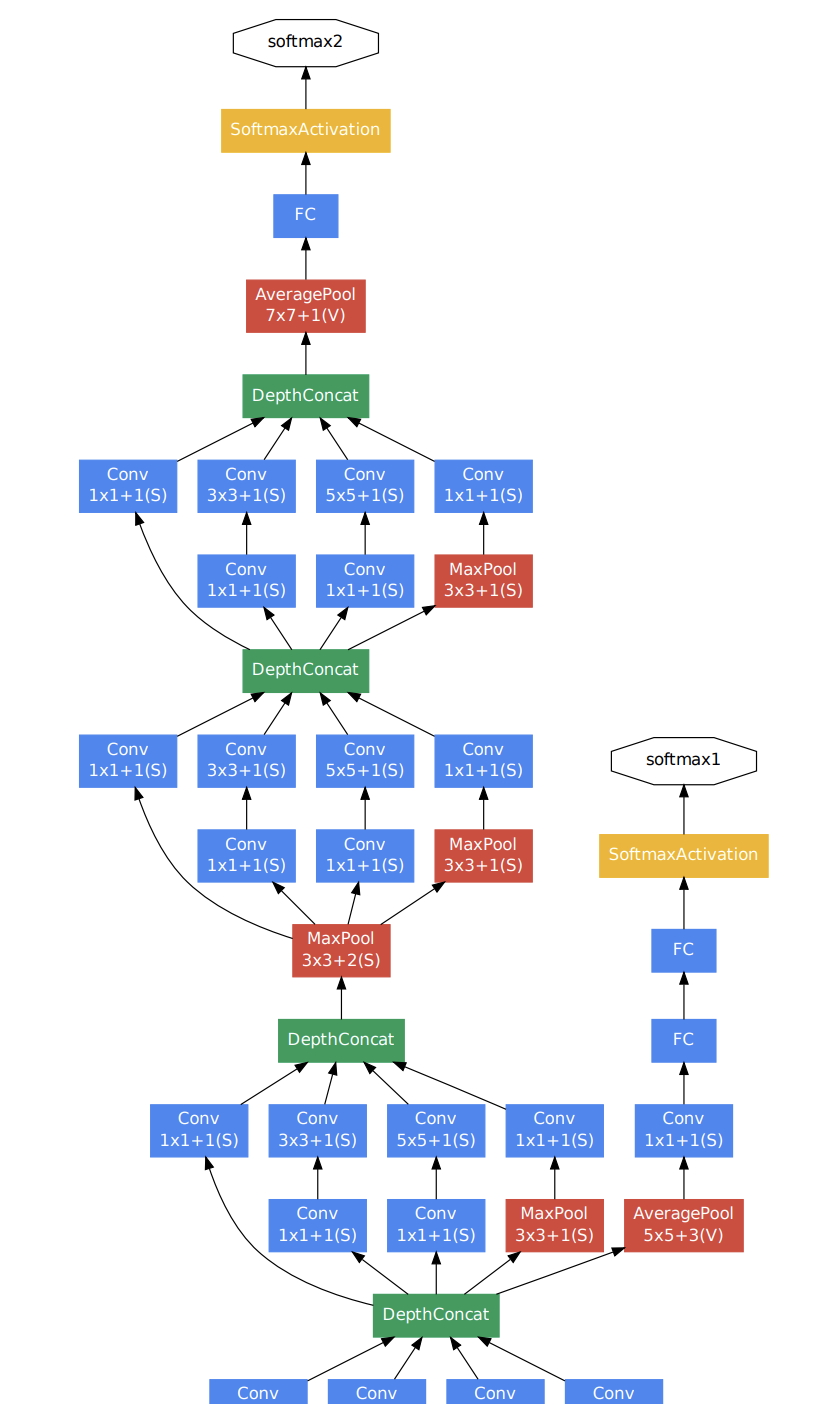 |
| 2014 VGGNet |
Stacks of small convolution filters (as opposed to one large filter) to reduce the number of parameters in the network. | 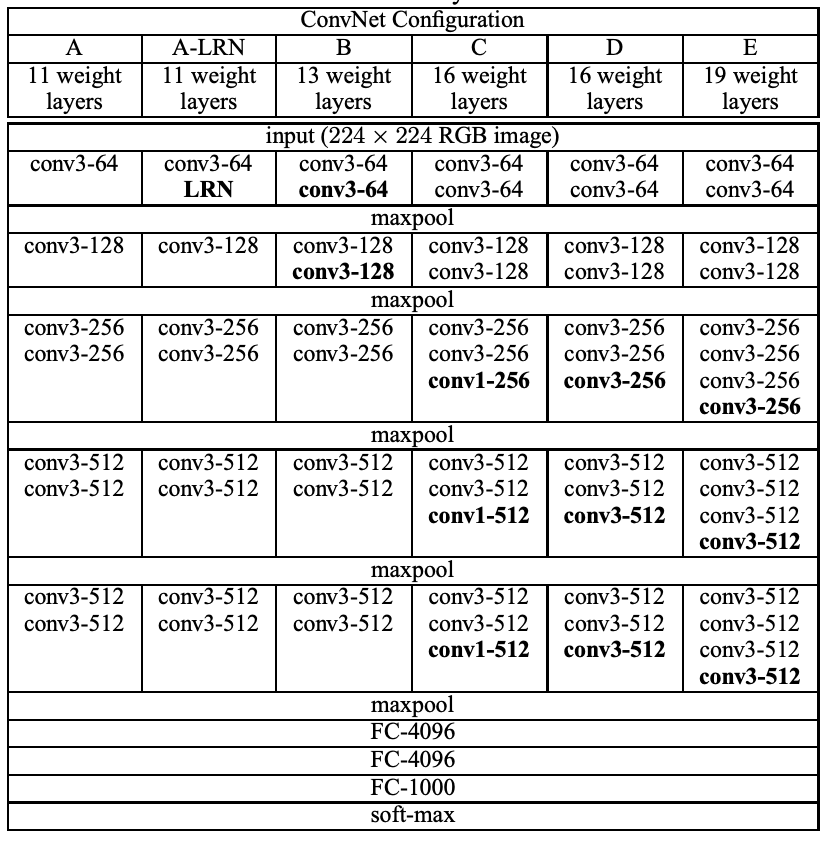 |
| 2015 ResNet |
Introduced skip connections (residual learning) to train very deep networks (152 layers). At the same time, the network is compact (few parameters for its size). | Partial depiction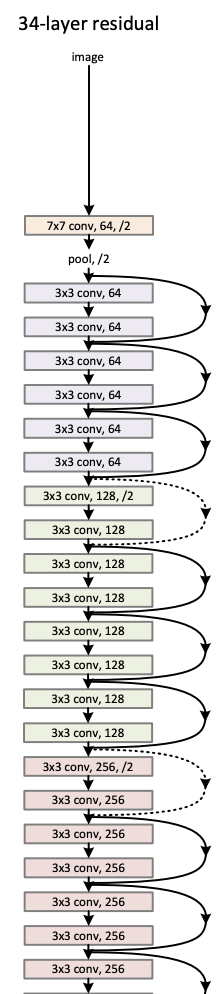 |
Network architectures continue to evolve today. So many architectures have been put into practice that we now need a taxonomy to categorize them.
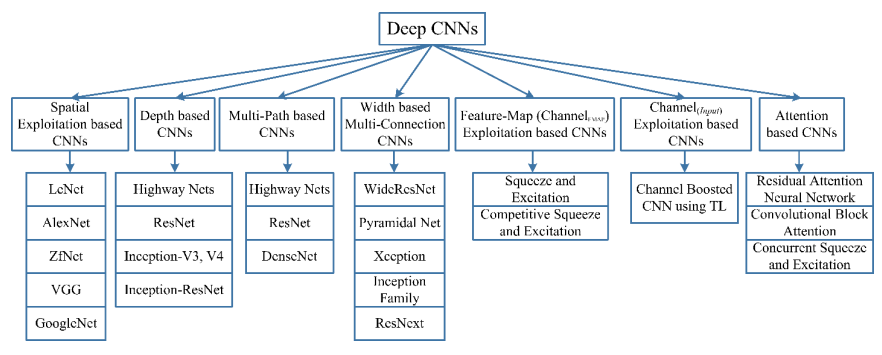
Recent trends
- Efficiently scaling CNNs: There are different ways to scale CNN-based networks. The EfficientNet family of networks shows that we don’t always need large CNN networks to get good results.
- Back to basics: The MLP-Mixer network does away with CNN layers altogether. It uses only simpler multi-layer perceptron (MLP) layers, resulting in networks with faster throughput, predicting more images per second than other network architectures.
- Transformers: Transformer-based networks, after their success with natural language processing (NLP), are being applied to image processing.
- Learning concepts: by training with images and their textual descriptions (multimodal learning), OpenAI created CLIP, a network that seems to have learned the concepts of images. Traditional image classification relied on extracting features from the images. They work well on images with the same characteristics but fail when they are different. For example, they identify the picture of a banana but not the sketch of a banana. On the other hand, CLIP seems to have learned the concept of the images. It identifies pictures and sketches of bananas (see the illustration in the article)
Keeping up with new developments
Papers with Code maintains a leaderboard of the state of the art, including links to the papers that describe the network used to achieve each result.